Find Word In Pdf File Python
For the first example lets scrape a 10-k form from Apple. The path is specified which indicates the path for the folder where the file is located.

Pin On Kutilstvi A Remesla
You just have to change the file.

Find word in pdf file python. Formatstrtypepage Extract text from the 50th page text pageextractText printtext if __name__ __main__. Print pdfReadernumPages numPages property gives the number of pages in the pdf file. Import pypdf2 from PyPDF2 import PdfFileReader def extract_pdfTextpath.
Click Download as Microsoft Word to save it as word file. It is widely used across every industry such as in government offices healthcare and even in. From win32com import client ie clientDispatchInternetExplorerApplication ieNavigatetest_filepdf ieDocumentprintAll Traceback most recent call last.
PrintThere are strkeywords__len__ keyword in the pdf file. Similarly you can extract all the images from the Word documents spreadsheets presentations with the exact above-mentioned python code for PDF document. Click More actions Open with Google Docs.
Import PyPDF2 import textract from nltktokenize import word_tokenize from nltkcorpus import stopwords def searchInPDFfilename key. Python-docx work with MS Word docx files. Apply concept of TF-IDF for calculating weights of.
Just open Google Drive click New File upload and upload your PDF file onto Drive. We are now going to search inside pdf files instead. For word documents with the docx extension Python module docx is a handy tool and the following shows how to import docx paragraphs with just 2 lines of code.
For example in our case it is 20 see first line of output. For this we need the pypdf2 package which you can install from your command line. Rakesh kumar word inputEnter any word that you want to find in text File word1 word word2 word f openrakeshtxtr data freadsplit if word in data or word1 in data or word2 in data.
Path DeepLearningpdf extract_pdfTextpath. PageObj pdfReadergetPagecount count 1 text. You can use comtypes from comtypesclient import CreateObject import os folder folder path wdToPDF CreateObject WordApplication wdFormatPDF 17 files oslistdir folder word_files f for f in files if fendswith doc docx for word_file in word_files.
Title num_pages pdf_reader. Python program to search a word in a text File program by. Word_path ospathjoin folder word_file pdf_path word_path if pdf_path -3 pdf.
Save list of extracted keywords in a DataFrame. You will be importing the PdfFileMerger module from the PyPDF2 package which helps to merge the pdf files. Import docx open connection to Word Document doc docxDocumentzen_of_pythondocx read in each paragraph in file result ptext for p in docparagraphs The docx2python package docx2python is another package we can use to scrape Word Documents.
From pathlib import Path from PyPDF2 import PdfFileReader Change the path below to the correct path for your computer. With openpath rb as f. Home creating-and-modifying-pdfs practice-files Pride_and_Prejudicepdf 1 pdf_reader PdfFileReader str pdf_path output_file_path Path.
I used the pdf document SHIP-ICE INTERACTION IN A CHANNEL found from trafifi as an example. Occurrences 0 pdfFileObj openfilenamerb pdfReader PyPDF2PdfFileReaderpdfFileObj num_pages pdfReadernumPages count 0 text while count num_pages. Convert PDF file to txt format and read data.
PrintWord Found in Text File else. PrintWord not found in Text File. Get file object reference to the file file openCworkspacepythondatatxt r read content of file to string data fileread get number of occurrences of the substring in the string occurrences datacountpython printNumber of occurrences of the word occurrences.
Open mode w as output_file. File stdin line 1 in file CPython25libsite-packageswin32comclientdynamicpy. Use findall function of regular expressions to extract keywords.
On the other hand to read scanned-in PDF files with Python the pytesseract package comes in handy which well see later in the post. Without downloading any other PDF converter tool you can use Google Drive to convert PDF to Word. First well just download this file to a local directory and save it as apple_10kpdf.
As one of the most commonly used documentation tools the MS Word oftentimes is peoples top choice for writing and sharing text. Pdf_path pdf_path. The old PDF file is previous that youve worked with whereas a new PDF file can be downloaded from the following link.
Line 496 in getattr raise AttributeError ss selfusername attr AttributeError. According to my pdf reader the word ship is written 83 times. Home Pride_and_Prejudicetxt 2 with output_file_path.
PDF or Portable Document File format is one of the most common file formats in todays time. Pdf PdfFileReaderf get the 50th page page pdfgetPage50 printpage printPage type. PdfReader PyPDF2PdfFileReader pdfFileObj Here we create an object of PdfFileReader class of PyPDF2 module and pass the pdf file object get a pdf reader object.
3 title pdf_reader. Py -m pip install pypdf2. Image Extraction from Excel PPT or Word Docs using Python.
Approach 1 unboxed.

Twezlisixazzfm

Pin On Word Search

Pin On Python Tutorial
Automate The Boring Stuff With Python
Automate The Boring Stuff With Python
Automate The Boring Stuff With Python

How To Scrape A Website That Requires Login With Python Isaac Vidas This Is Not For You Python Website Scrapes

How To Read Large Text Files In Python Journaldev

Pin On Code Geek

Working With Pdfs In Python Reading And Splitting Pages Stack Abuse

Here Is A Simple Way To Convert Pdfs To Word Documents In Google Drive Educational Technology Apps For Teachers Google Education

Pin On Software
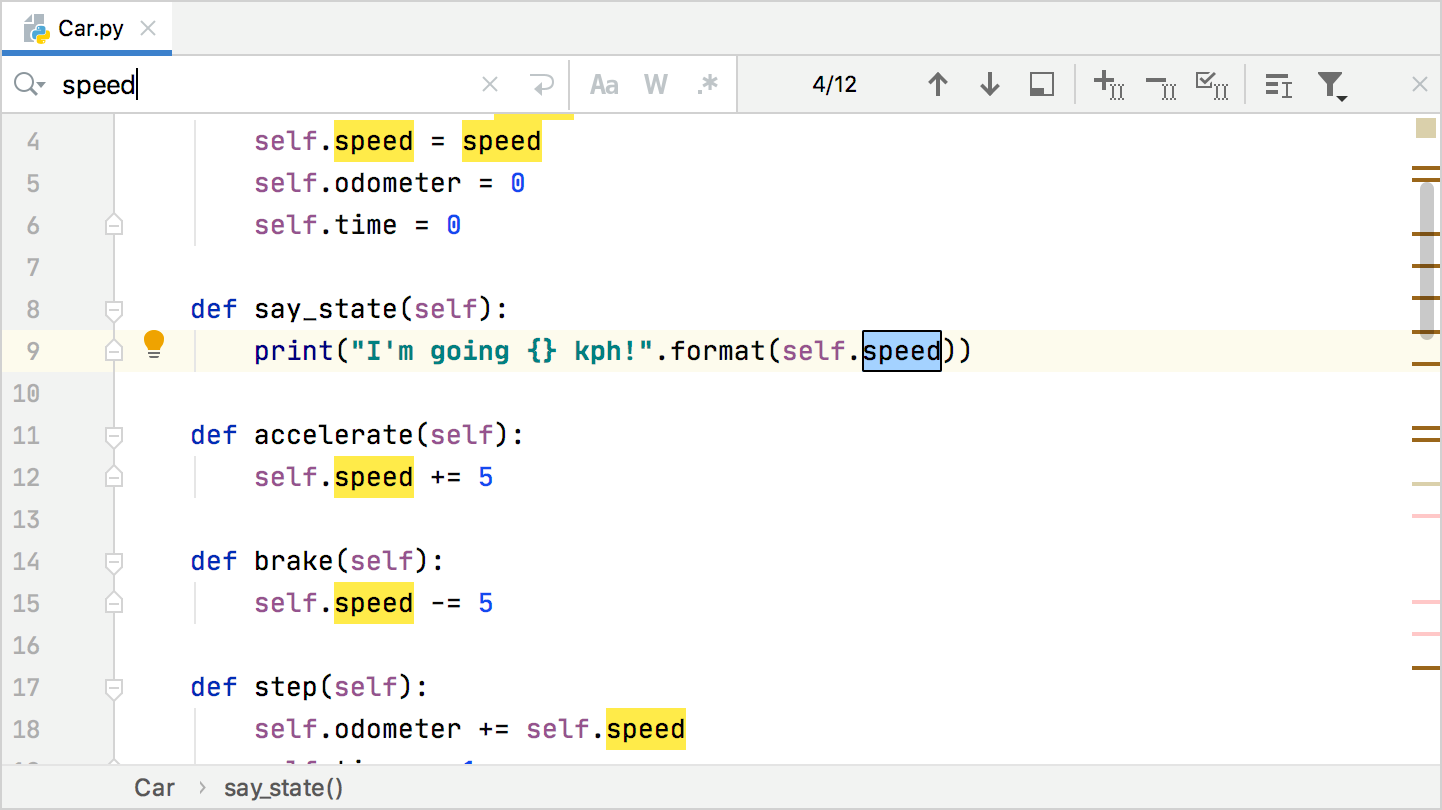
Search For A Target Within A File Pycharm

Pin On Tutorials Tips

Pin On Python

Working With Pdfs In Python Reading And Splitting Pages Stack Abuse
Working With Pdfs In Python Reading And Splitting Pages Stack Abuse

Pin On Python Tutorial

Pin On Fun Ny Stuff